
I. Giới thiệu
Gần đây mình có tìm hiểu cơ bản về khái niệm cũng như cách hoạt động của Clustered index và Secondary index mình rút ra được khá nhiều kiến thức. Trong bài viết này mình sẽ chia sẻ cách nó tìm kiếm dữ liệu và từ đó ta có thể làm gì để tối ưu cho hệ thống của chúng ta.
II. Khái niệm cơ bản
1. Storage
– Đầu tiền thì chúng ta cần biết InnoDB là một storage engine trong MySQL và trong MySQL hỗ trợ nhiều loại storage engine khác nhau, hiện tại InnoDB đang được đặt làm mặc định khi tạo table, có một điều chúng ra cần biết là database sẽ có nhiều tables và mỗi table có thể có storage engine khác nhau, mỗi storage engine có ưu nhược điểm riêng và chúng phù hợp với các tình huống sử dụng khác nhau. Các bạn muốn biết nhiều hơn về các loại storage engine thì tìm hiểu nha. Dưới đây là hình ảnh mô tả cho bạn biết Storage engine ở đâu.
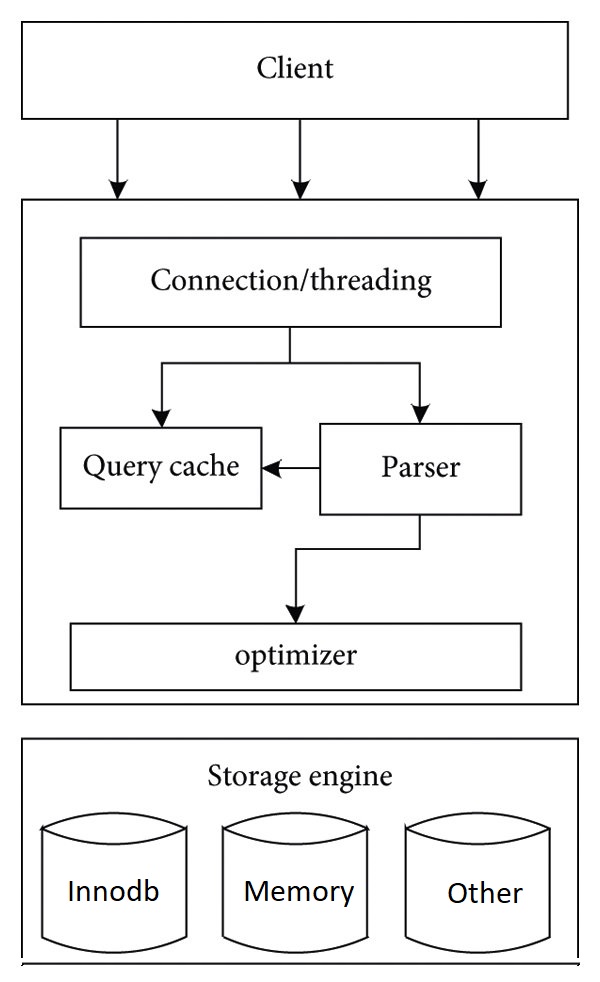
– Mô tả ngắn gọn các thành phần:
Parser: Phân tích và chuyển đổi câu lệnh SQL thành cấu trúc dữ liệu MySQL có thể hiểu được
Query cache: Lưu trữ kết quả của các truy vấn đã thực hiện trước đó để tăng hiệu suất
Optimizer: Tối ưu query đưa ra các chiến lược phù hợp với từng loại storage engine như chọn chỉ mục…
Storage engine: Mỗi storage engine sẽ có các đặc điểm và logic xử lý khác nhau
2. Kiểu lưu trữ
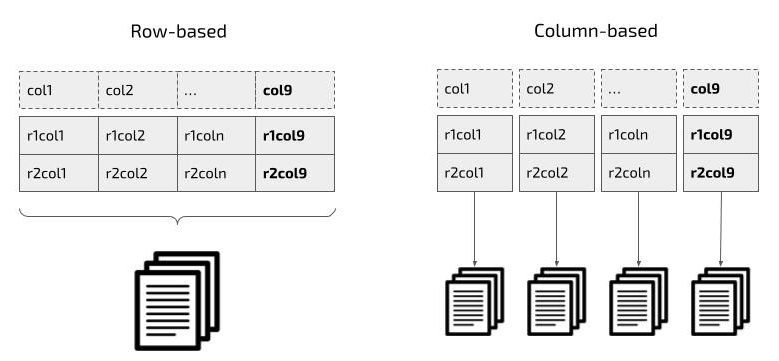
– Storage InnoDB lưu trữ dữ liệu theo kiểu Row-based và lưu trên các pages nó phù hợp với các thao tác CRUD. Một số storage engine khác sử dụng kiểu lưu trữ Column-based, trong đó mỗi column sẽ được lưu trữ tách biệt trên các pages riêng biệt, mỗi page chứa một phần dữ liệu của column đó, phù hợp với hệ thống phân tích dữ liệu.
Row-based: Truy xuất tất cả dữ liệu của row, mất nhiều thời gian khi chỉ cần vài column.
Column-based: Chỉ truy xuất dữ liệu của column, tiết kiệm thời gian và tận dụng xử lý song song.
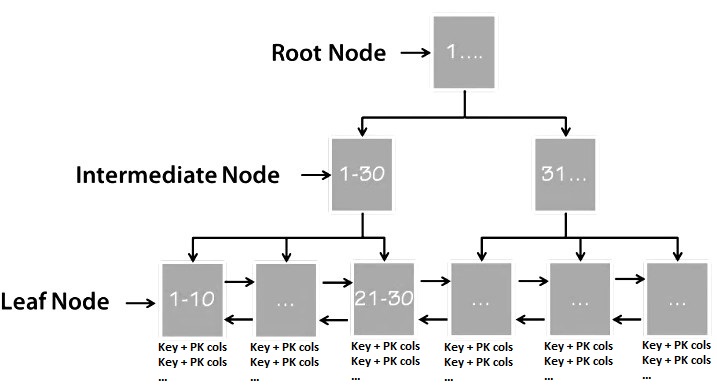
3. Tổng quan về B+Tree trong InnoDB
– Cấu trúc B+Tree trong InnoDB được sử dụng để lưu trữ các indexs bao gồm cả clustered index(Primary key) và các secondary index. B+Tree trong InnoDB có 3 loại node chính là:
Root Node: Có thể là Internal node hoặc Leaf node tùy vào dữ liệu hiện tại
Internal Node: tác dụng của nó là để điều hướng dựa vào primary key và pointer liên kết
Leaf Node: lưu trữ dữ liệu bản ghi thực tế và các pointer liên kết
Ví dụ hình ảnh về cấu trúc
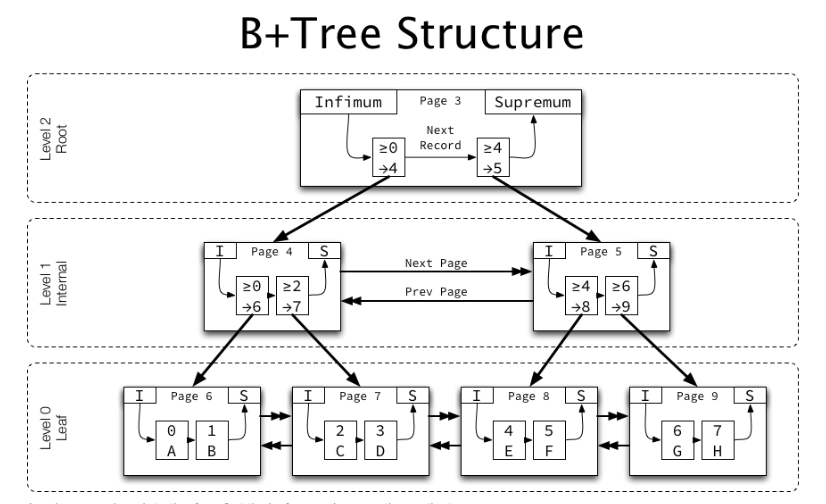
Các bạn có thể thấy trường hợp này Root Node chính là Internal Node chỉ dùng để điều hướng.
– Ví dụ mình tìm kiếm page chứa primary key bằng 2 chính là page 7.
Đầu tiên mình vào page 3 do primary key mình bằng 2 chỉ phù hợp hợp điều kiện >=0 mình sẽ được điều hướng đến page 4
Tiếp tục cầm primary key bằng 2 đó so sánh tiếp và phù hợp với >=2 mình sẽ được điều hướng đến page 7
Sau khi đã tìm được page để lấy được dữ liệu sẽ tùy vào loại index cũng như query hệ thống có cách xử lý khác nhau, sau khi đi chi tiết về cách hoạt động của từng loại index các bạn sẽ hiểu rõ hơn.
4. Page
– Trong InnoDB dữ liệu được lưu trữ trên các pages, một page thường có kích thước mặc định là 16KB các loại kích thước page là: 4KB, 8KB, 16KB, 32KB, 64KB InnoDB sử dụng khá nhiều loại page trong bài này mình sẽ chỉ chủ yếu nói về index page. Chúng ta tìm hiểu qua cấu trúc của page

FIL Header (38 bytes): Lưu trữ thông tin metadata cơ bản, đối với loại trang Index sẽ có các pointers đến trang trước và trang tiếp theo ở cùng một cấp độ (Các bạn có thể xem lại hình ảnh phần B+Tree để thấy)
INDEX Header (36 bytes): Lưu thông tin về loại index, page level, số lượng record, thống kê số byte đưuọc sử dụng bởi các record đã xóa…
FSEG Header (20 bytes): Metadata liên quan đến phân đoạn (segment) lưu trữ để hỗ trợ quản lý không gian lưu trữ.
System Records (26 bytes): Lưu trữ các bản ghi hệ thống đặc biệt I(Infimum), S(Supremum)
User Records: Chứa các bản ghi dữ liệu của người dùng các bản ghi này đã được sắp xếp và liên kết với nhau.
Free Space(Kkông gian trống): là các phần chưa được sử dụng hoặc dữ liệu đã bị xóa đang chiếm không gian lưu trữ (Phần này cần phải lưu ý vì nó ảnh hường khá nhiều đến query)
Page Directory: Lưu trữ các pointers đến các user records và các mục trong page directory được sắp xếp tăng dần theo thứ tự của primary key giúp query range xử lý tốt hơn.
FIL Trailer (8 bytes): Chứa thông tin check tính toàn ven của trạng và lưu số thứ tự trang để xác nhận liên kết giữa các trang
– Tóm lại thì khá nhiều thông tin trong page và mỗi phần đều có vài trò riêng nhằm quản lý cũng như tối ưu tìm kiếm dữ liệu.
III. Index page
Ok sau khi có một vài khái niệm cơ bản giờ đến lúc ta tìm hiểu chi tiết về Clustered index và Secondary index
1. Clustered index
Clustered Index là loại chỉ mục đặc biệt:
– Lưu trữ dữ liệu thực tế của bảng.
– Dữ liệu được sắp xếp theo primary key.
– Nếu bảng không có primary key, InnoDB sẽ chọn một unique key làm primary key (nếu có). Nếu không có unique key, InnoDB sẽ tạo ra một primary key ẩn.
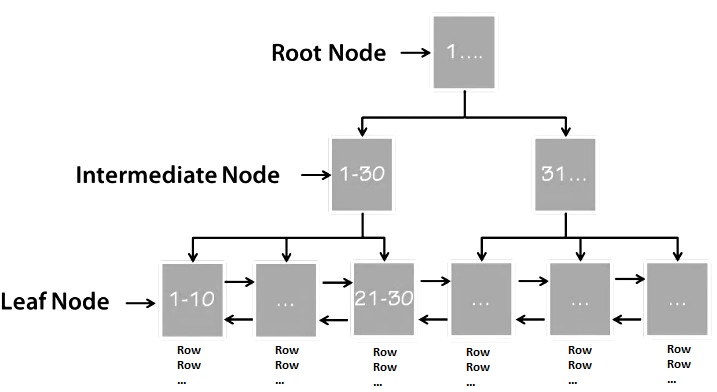
– Khi tìm kiếm dữ liệu với primary key:
Hệ thống điều hướng từ Root Node qua các Internal Node để tìm đến Leaf Node chứa dữ liệu thực tế.
Dữ liệu được truy xuất trực tiếp từ Clustered Index mà không cần tham chiếu đến nơi khác.
2. Secondary index
Secondary Index được sử dụng để tăng tốc độ truy vấn dựa trên các cột không phải primary key. Mỗi Secondary Index lưu:
– Giá trị của cột được chỉ mục.
– Giá trị primary key để tham chiếu đến Clustered Index.
– Trường hợp 1: Nếu truy vấn yêu cầu dữ liệu nằm ngoài Secondary Index, hệ thống:
Tìm kiếm trong Secondary Index để lấy giá trị primary key.
Từ primary key tham chiếu đến Clustered Index để tìm page sau khi tìm được page sẽ sử dụng thuật toán Binary Search để truy xuất dữ liệu thực tế.
– Trường hợp 2: Nếu truy vấn chỉ yêu cầu cột nằm trong Secondary Index, hệ thống trả về dữ liệu ngay mà không cần tham chiếu đến Clustered Index.
IV. Một số phương pháp tối ưu
1. Nên đặt primary key như nào và tại sao
Thông thường primary key sẽ được đặt theo kiểu Integer và giá trị tự động tăng như vậy hiệu suất sẽ cao hơn vì:
– Kích thước lưu trữ nhỏ, bên trên các bạn có thể thấy mỗi Secondary index sẽ bao gồm cả primary key để tham chiếu đến Clustered index nếu cần => nếu primary key lớn sẽ dẫn đến lãng phí tài nguyên, kích thước lớn hơn cũng làm chậm truy vấn
– Giảm số lượng free space đối với trường hợp primary không tuần tự(Tùy trường hợp): Cùng xem qua ví dụ không tuần tự bên dưới
Giả sử chúng ta có 3 pages full
Page 1: [1, Alice], [2, Bob], [3, Charlie]
Page 2: [4, David], [6, Eve], [7, Frank]
Page 3: [8, Grace], [9, Hannah], [10, Ian]Bạn insert [5, Jack] => kết quả là vị trí phù hợp của 5 ở page 2 nhưng page lại đang full nên để xử lý page split sẽ xảy ra và kết quả là:
Page 1: [1, Alice], [2, Bob], [3, Charlie]
Page 2: [4, David], [5, Jack], [6, Eve]
Page 4: [7, Frank] //data free
Page 3: [8, Grace], [9, Hannah], [10, Ian] Các bạn có thể thấy dữ liệu vẫn được sắp xếp tuần tự, nhưng page 4 đã có free space, nếu bạn insert primary key tuần tự thì trường hợp bạn insert 5 vào là không thể xảy ra vì số lớn nhất đang là 10 và nó cứ tăng lên thôi lúc đó có thể có free space nhưng nó vẫn được sử dụng hợp lý.
– Lưu ý primary key tự động tăng sẽ không phù hợp với xóa nhiều xem ví dụ các bạn sẽ hiểu:
Page 1: [1, Alice], [2, Bob], [3, Charlie]
Page 2: [4, David], [6, Eve], [7, Frank]
Page 3: [8, Grace], [9, Hannah], [10, Ian]
Giả sử các bạn xóa 2, 3, 4 ,7 và insert 11, 12
Page 1: [1, Alice] //data free (không được sử dụng lại vì primary luôn tăng dần)
Page 2: [6, Eve] //data free (không được sử dụng lại vì primary luôn tăng dần)
Page 3: [8, Grace], [9, Hannah], [10, Ian]
Page 4: : [11, hoa], [12, mai]– Thêm ví dụ về update cũng gây tình trạng xuất hiên data free:
Page 1: [1, Alice], [2, Bob], [3, Charlie]
Page 2: [4, David], [6, Eve], [7, Frank] // Page 2 đầy
Page 3: [8, Grace], [9, Hannah], [10, Ian]
Nếu bạn update id 6 có kích thước lớn hơn dữ liệu cũ trong khi page 2 đang full thì tình trạng page split cũng xảy ra và trường hợp này kết quả là
Page 1: [1, Alice], [2, Bob], [3, Charlie]
Page 2: [4, David], [6, Eve (updated)]
(Dữ liệu mới của id 6 nằm trong Page 2 nhưng chiếm nhiều chỗ hơn trước, khiến chỉ một phần dữ liệu của Page 2 được giữ lại.)
Page 4: [7, Frank]
Page 3: [8, Grace], [9, Hannah], [10, Ian]
Tóm lại riêng đối với các reports nhiều dữ liệu chúng ta nên hạn chế sử dụng kiểu dữ liệu không có kích thước cố định, đối với column nào convert từ varchar sang dạng số được thì chuyển sang lưu dạng số ví dụ như status, country, updated_at, created_at… và column nào ít sử dụng nhưng có text dài nên tách ra table khác tránh tình trạng không sử dụng nhưng vẫn phải load khi thực hiện query tại clustered index, nếu report xóa nhiều thì không nên sử dụng primary tự động tăng.
– Một vài ảnh hưởng của Data free
Lãng phí không gian lưu trữ như đã ví dụ
Ảnh hưởng đến truy vấn(Tăng số lần đọc từ ổ đĩa) xem ví dụ bạn sẽ rõ:
Trước khi phân mảnh:
Page 1: [1, Alice], [2, Bob], [4, Charlie]
Page 2: [5, David], [6, Eve], [7, Frank]
Page 3: [8, Grace], [9, Hannah], [10, Ian]
Chỉ cần đọc 3 trang là đủ để truy vấn SELECT * FROM table WHERE id > 0
Sau khi phân mảnh (do update hoặc delete…):
Page 1: [1, Alice], [2, Bob]
Page 2: [3, Charlie], [4, David]
Page 3: [5, Eve]
Page 4: [6, Frank]
Page 5: [7, Grace]
Page 6: [8, Hannah], [9, Ian]
Giờ đây, để thực hiện truy vấn SELECT * FROM table WHERE id > 0, bạn cần đọc 6 trang, thay vì 32. Tối ưu xử lý data free
Xử lý data free hiện tại mình tìm hiểu thì có 3 phương pháp phổ biến
– Phương pháp 1:
OPTIMIZE TABLE your_table_name;+ Cách hoạt động:
MySQL sẽ tạo một table temp để lưu dữ liệu, tái cấu trúc table gốc, và sau đó thay thế table gốc bằng table mới.
Giải phóng các trang chứa dữ liệu không cần thiết (khoảng trống).
+ Nhược điểm:
Quá trình này có thể tiêu tốn tài nguyên và làm gián đoạn hoạt động trên table (lock table tạm thời).
Không hiệu quả đối với bảng rất lớn nếu không đủ không gian lưu trữ.
– Phương pháp 2:
ALTER TABLE your_table_name ENGINE=InnoDB;Tương tự như OPTIMIZE TABLE, nhưng đôi khi sẽ hiệu quả hơn trong trường hợp OPTIMIZE TABLE không hoạt động tốt.
– Phương pháp 3:
Phương pháp mạnh mẽ nhất, đặc biệt với bảng rất lớn hoặc có quá nhiều phân mảnh có thể thi hồi tối đa không gian trống(free space):
Dump dữ liệu ra file
mysqldump -u username -p database_name your_table_name > your_table_name.sql
Xóa bảng và tạo lại
DROP TABLE your_table_name;
CREATE TABLE your_table_name (...);
Nhập lại dữ liệu
mysql -u username -p database_name < your_table_name.sql+ Nhược điểm:
Cần downtime và tốn thời gian với bảng lớn. (Bạn có thể đặt tên khác, sau khi xong thì đổi lại tên table để hạn chế downtime nhất có thể, nhưng bù lại thì tốn bộ nhớ trong quá trình thực thi vì nó gần giống với clone ra một table mới)
3. Tối ưu LIMIT OFFSET
Chắc hẳn chúng ta đều biết nếu dữ liệu cần lấy sau khi truy vấn có khoảng 3000000 và LIMIT của bạn là 20 OFFSET 2500000 thì trước khi lấy được 20 bản ghi bạn sẽ phải đi qua 2500000 bản ghi trước đã và thông thường khá tốn tài nguyên nếu nó cần truy cập vào Clustered index(Toàn bộ dữ liệu thực tế của table ở đây) truy vấn lấy column hoặc so sánh điều kiện tại Clustered index. Mình có tim hiểu thì có 2 phương pháp xử lý nhanh hơn nhưng tùy vào query cũng như index của bạn như nào để xem tiến hành triển khai có hợp lý không.
– Phương pháp 1:
Thay vì dùng OFFSET, hãy tận dụng giá trị last id(Primary key) từ truy vấn trước để làm điểm bắt đầu cho lần truy vấn tiếp theo (Có lưu ý là trường hợp này cần phải ORDER BY id).
+ Cách thực hiện:
Truy vấn lần đầu:
SELECT * FROM your_table ORDER BY id LIMIT 5;
// Sau khi xử lý xong dữ liệu lấy id cuối cùng: Giả sử last_fetched_id = 2500000.
Truy vấn tiếp theo:
SELECT * FROM your_table WHERE id > 2500000 ORDER BY id LIMIT 5;
...+ Lợi ích: Tránh việc MySQL phải duyệt qua 2.5 triệu bản ghi.
– Phương pháp 2:
Khi truy vấn sử dụng Covering Index, MySQL có thể trả về kết quả trực tiếp từ index mà không cần truy cập vào bảng dữ liệu (Clustered index), giúp tăng tốc truy vấn.
+ Cách thực hiện: Giả sử bạn có table với các cột id(Primary key), name, và age, và bạn có index trên cột age.
Phần này chỉ thao tác với Secondary index và lấy ra ids
SELECT id FROM your_table WHERE age > 5
ORDER BY age
LIMIT 5 OFFSET 2500000;
Sau khi có danh sách ids sử dụng query mới để lấy dữ liệu trong Clustered index
SELECT * FROM your_table WHERE id IN (ids);+ Lợi ích: tiết kiệm tài nguyên, không cần truy cập vào Clustered index để query lấy dữ liệu vì MySQL có thể trả về kết quả chỉ từ Secondary index. Từ kết quả của Secondary index lại dùng primary key để lấy dữ liệu trong clustered index sẽ nhanh hơn rất nhiều.
Lưu ý: Cần có một index bao gồm tất cả các cột trong query để đảm bảo MySQL chỉ sử dụng Secondary index mà không phải truy cập Clustered index.
4. Xử lý full memory cho hiệu quả
Hiện tại phổ biến khi xử lý data trong job chúng ta thường gặp tình trạng dữ liệu quá nhiều nên ta sử dụng chunk hoặc chunk theo id(chunk 1: id > 0 ORDER BY id LIMIT 1000, chunk 2: WHERE id > (last id output chunk 1) ORDER BY id LIMIT 1000) để chia nhỏ data như vậy khá OK nhưng có 1 vài trường hợp khá chậm mình ví dụ: Mình có 1 query trong table có khoảng 150 triệu rows sau đó mình GROUP BY còn khoảng 3 triệu rows thời gian query mất 5p do mình đã GROUP nên nếu sử dụng chunk thì mỗi query mất ít nhất cũng là 5p rồi, chúng ta còn chưa tính các trường hợp query về sau càng ngày càng lâu do phải đi qua các row cũ đã đọc từ các chunk trước đó rồi mới tìm đến offset của chunk hiện tại, tiếp giả sử mình chunk mỗi lần 10000 bản ghi => sẽ cần 300 lần query => để hoàn thành mình sẽ mất ít nhất khoảng hơn 1 ngày =)). Các bạn có thể thấy để tránh tình trạng full memory nên chúng ta thường xử lý theo chunk nhưng trường hợp này là không phù hợp mình có tìm hiểu đưuọc thêm 2 phương pháp giải quyết cho trường hợp này là:
Phương pháp 1: Sử dụng CURSOR, giả sử client là PDO kết nối với MySQL ta nên sử dụng CURSOR kết hợp với Streaming, giúp xử lý dữ liệu từng row một mà không cần tải toàn bộ kết quả vào bộ nhớ.
Phương pháp 2: Sử dụng TEMPORARY của MySQL lưu trữ kết quả đầu ra và đánh index sau đó truy vấn trong 3 triệu rows(Nó sẽ chỉ có tác dụng trong session hiện tại, khi kết thúc table temp sẽ bị xóa)
Lưu ý: Đối với 2 cách này các bạn sẽ thấy CURSOR thì sẽ giữ connection trong quá trình xử lý còn TEMPORARY thì tốn bộ nhớ RAM(Nếu dữ liệu lớn RAM không đủ sẽ được lưu trên DISK thay vì trên RAM) các bạn nên cân đối sao cho hợp lý. Còn cách sử dụng các bạn tìm hiểu nha search là ra thôi.
V. Kết luận
Trên đây là cơ bản những gì mình tìm hiểu được để tối ưu storage InnoDB trong MySQL, nếu sử dụng các bạn nên đi sâu chi tiết để tránh các trường hợp không mong muốn khi sử dụng. Có vài cách phổ biến khác để tối ưu như Partitioning, Replication cách nó hoạt động khá dễ hiểu chỉ riêng Sharding là khó triển khai vì nó còn liên quan đến Transaction do dữ liệu của nó chia nhỏ ở các server khác nhau nên tóm lại không vào đường cùng thì không nên sử dụng Sharding =)).
Cảm ơn các bạn đã đọc.